GKE 上的 gRPC 性能基准测试
gRPC 性能基准测试现已迁移至 GKE 上运行,结果相似,但灵活性大大提高。
背景
gRPC 性能测试需要一个测试驱动器和工作器(一个或多个客户端和一个服务器),如gRPC 性能基准测试中所述。每个测试可能有一个不同的配置或“场景”,它被传递给驱动器并以 JSON 文件的形式指定。以前,驱动器由持续集成过程运行,工作器在长期运行的 GCE 虚拟机上运行。这导致了一些限制:
测试是按顺序运行的,并且由于在(相同的)固定虚拟机上运行,因此难以并行化。
无法保证每个测试开始时虚拟机的状态都相同。
运行手动实验需要配置新的虚拟机,这是一个手动过程,或者复用现有虚拟机,存在与其他用户冲突以及虚拟机处于未知状态的风险。
在 Kubernetes 上进行基准测试
当前框架的核心是一个自定义控制器,用于管理 Kubernetes 的 LoadTest 资源。此控制器必须部署到 Kubernetes 集群中才能在其上运行负载测试。该控制器使用 kubebuilder 实现。控制器的代码存储在 Test Infra 仓库中。有关各个 LoadTest 字段的更多文档,请参阅 LoadTest 实现。
LoadTest 配置指定要为测试创建的驱动器、客户端和服务器 Pod。一旦配置应用于集群(例如,使用 kubectl apply -f),控制器将创建 Pod 并运行测试。如果多个配置应用于集群,只要有可用资源,控制器就会创建 Pod,从而允许测试并行运行。
示例包括可以直接应用的基本配置,以及需要额外步骤和参数替换的模板。
基本配置依赖于控制器每个版本捆绑的 **clone**、**build** 和 **runtime** 工作器镜像。clone 和 build 镜像用于构建 gRPC 二进制文件,这些二进制文件将传递给运行时容器。这些配置适用于作为示例和一次性测试。
模板配置依赖于在开始测试之前构建的工作器镜像。这些**预构建镜像**包含 gRPC 二进制文件,无需在每次测试前进行克隆和构建。模板替换用于指向工作器镜像的位置。这些配置适用于在相同 gRPC 版本上运行一批测试,或重复运行相同的测试。
除了控制器之外,Test Infra 仓库还包含一套工具,其中包括一个测试运行器和用于构建和删除预构建工作器镜像的工具,以及一个仪表盘实现。
与预构建工作器相关的工具内部使用 gcloud 并依赖于 GKE。除此之外,框架的所有组件都构建在 Kubernetes 本身之上,并且独立于 GKE。也就是说,应该可以在自定义 Kubernetes 集群或另一个云提供商的 Kubernetes 产品上部署控制器并运行测试。
集群设置
运行基准测试作业的集群必须配置有节点池,其大小应与它应支持的并发测试数量相对应。控制器使用 pool 作为各种 Pod 类型的节点选择器。工作器 Pod 具有相互反亲和性,因此每个 Pod 需要一个节点。
例如,我们持续集成设置中使用的节点池配置如下:
| 池名称 | 节点数量 | 机器类型 | Kubernetes 标签 |
|---|---|---|---|
| system | 2 | e2-standard-8 | default-system-pool:true, pool:system |
| drivers-ci | 8 | e2-standard-2 | pool:drivers-ci |
| workers-c2-8core-ci | 8 | c2-standard-8 | pool:workers-c2-8core-ci |
| workers-c2-30core-ci | 8 | c2-standard-30 | pool:workers-c2-30core-ci |
由于我们的测试中每个场景需要一个驱动器和两个工作器,此配置支持在 8 核机器上同时进行四个测试,在 30 核机器上同时进行四个测试。驱动器所需资源较少,且没有相互反亲和性。我们发现将其调度到节点计数设置为所需驱动器数量的两核机器上比调度到更大的共享机器上更方便,因为这允许驱动器池与工作器池一起调整大小。控制器本身调度在 system 池中。
除了持续集成中使用的池之外,我们的集群还包含可用于即席测试的其他节点池:
| 池名称 | 节点数量 | 机器类型 | Kubernetes 标签 |
|---|---|---|---|
| drivers | 8 | e2-standard-8 | default-driver-pool:true, pool:drivers |
| workers-8core | 8 | e2-standard-8 | default-worker-pool:true, pool:workers-8core |
| workers-32core | 8 | e2-standard-32 | pool:workers-32core |
一些池带有 default-*-pool 标签。这些标签指定了在 LoadTest 配置中未指定池时要使用的池。通过上述配置,这些测试(例如 示例中指定的测试)将使用 drivers 和 workers-8core 池,并且不会干扰持续集成作业。默认标签是作为控制器构建的一部分定义的:如果未设置,控制器将仅运行显式指定 pool 标签的测试。
控制器部署
构建和部署控制器的步骤在部署文档中描述。
持续集成
我们的持续集成设置在 gRPC Core 仓库的gRPC OSS 基准测试 README 中有描述。主要的持续集成作业使用脚本 grpc_e2e_performance_gke.sh 来生成链接到gRPC 性能基准测试页面上的仪表盘所显示的数据。
每次持续集成运行都包含三个阶段:
- 生成测试配置。
- 构建并推送工作器镜像。
- 运行测试。
每次持续集成运行都使用 8 核工作器池执行 122 个测试,使用 30 核工作器池执行 98 个测试。每个测试运行一个测试场景。使用 C++、C#、Java 和 Python 工作器的测试在两个池上运行。使用 Node.js、PHP 和 Ruby 工作器的测试仅在 8 核池上运行。所有这些组合的配置生成耗时可忽略不计(约 1 秒)。
持续集成中使用的配置需要包含要测试的 gRPC 二进制文件的工作器镜像。这些镜像仅依赖于工作器的语言,因此这些预构建镜像会提前构建并推送到镜像仓库。此过程大约需要 20 分钟。
一个测试运行器管理向集群应用测试的速率,收集测试结果和日志,并在测试成功完成后删除测试。每个池允许同时运行两个测试。此阶段大约需要 50 分钟才能完成。
每个测试场景配置为运行 30 秒,外加 5 秒的预热期(Java 为 15 秒)。这为每个测试的运行时间设定了下限。在 8 核池中观察到的 122 个测试(其中 16 个在 Java 中)同时运行两个测试的运行时间表明,Pod 创建和删除引入的开销很小,每个测试约 12.8 秒。
配置生成
由于我们正在运行数百个主要共享相同组件(各种语言的驱动器和工作器)的测试,因此有必要生成包含重复的驱动器和工作器配置,而仅在测试场景上有所不同的配置。此外,每个配置必须具有唯一的名称,因为这是应用于 Kubernetes 集群的资源的要求。
我们通过使用工具生成负载测试配置来解决这些问题。该工具存储在gRPC Core 仓库中,测试场景也在此定义。
预构建镜像
为持续集成生成的配置使用一组预构建镜像。这些镜像在运行测试之前构建并推送到镜像仓库。镜像在每次测试运行结束时删除。
有关用于准备和删除镜像的工具的详细信息,请参阅将预构建镜像与 gRPC OSS 基准测试结合使用。
测试运行器
测试运行器获取先前生成的测试配置,将每个配置应用于集群,轮询每个 LoadTest 资源以检查完成情况,收集结果和 Pod 日志等工件,并(可选)在每个测试成功完成后删除资源。
测试运行器为需要集群上相同资源(例如 8 核或 30 核工作节点)的测试维护单独的“队列”。属于同一队列的测试配置不会一次性应用于集群,而是根据为每个队列设置的“并发级别”进行。我们的持续集成测试在两个队列中运行(对应于 8 核和 30 核工作节点)。每个队列的并发级别都设置为二。
一旦配置应用于集群,控制器将创建客户端、驱动器和服务器 Pod 来运行测试,监控测试执行,并更新 LoadTest 资源的状态。
测试运行器的设计可以解释如下:
使用测试运行器允许持续集成作业等待所有测试完成,收集测试工件,并准备包含结果的报告。
使用单独的队列(由每个测试配置中的注释指示)允许不要求相同集群资源的测试彼此独立管理。
使用有限的并发级别减少了同时应用于集群的测试数量。这有几个好处:
测试运行器上的负载减少了,因为集群上同时存在的 LoadTest 资源更少,并且运行器会定期轮询这些资源以检查完成情况。我们持续集成中的轮询间隔设置为 5 秒。
控制器上的负载减少了,因为它同时要控制的 LoadTest 资源更少。
每个测试的超时时间可以更短,因为控制器启动每个测试所需的时间更可预测。超时是必要的,以应对客户端或服务器 Pod 挂起并阻止测试完成的错误情况。这些情况很少见,但会累积并消耗集群资源,从而阻止其他测试运行。我们持续集成中的测试超时时间为 15 分钟。
并发级别可以设置得低于集群容量,允许用户运行一批测试而不会阻止其他用户同时运行测试。
在每个测试成功完成(并且收集了结果和日志)后删除测试的选项提供了更好的测试生命周期控制。
控制器的默认行为是将在集群上的 LoadTest 资源及其相关 Pod 保留直到达到设定的 TTL,然后将其删除。我们的持续集成为每个测试指定 24 小时的 TTL。
属于已完成 LoadTest 的 Pod 处于终止状态,因此不消耗集群上的任何资源。但是,终止的 Pod 可以随时进行垃圾回收。
如果我们让属于所有已完成测试的 Pod 留在我们的持续集成集群中,我们发现它们会在一小时内被垃圾回收。
如果删除成功完成的测试的 LoadTest 资源,则相关的 Pod 也会被删除。在这种情况下,属于**未成功**测试的 Pod(数量很少,可能对调试有用)将保留在集群中,直到达到 24 小时的 TTL。
仪表盘
持续集成测试结果保存到 BigQuery。存储在 BigQuery 中的数据随后复制到 Postgres 数据库,用于在仪表盘上进行可视化。
仪表盘的代码以及主要持续集成仪表盘的配置都存储在 Test Infra 仓库中。这带来了以下好处:
通过更新存储的配置来维护主仪表盘,而不是直接在 UI 中更新。
用户可以部署自己的仪表盘,使用自己的配置。
这与以前的基准测试仪表盘(使用 Perfkit Explorer 构建)形成对比,后者是通过直接在 UI 中更新来维护的,并且用户无法轻松复制。
有关详细信息,请参阅仪表盘实现。
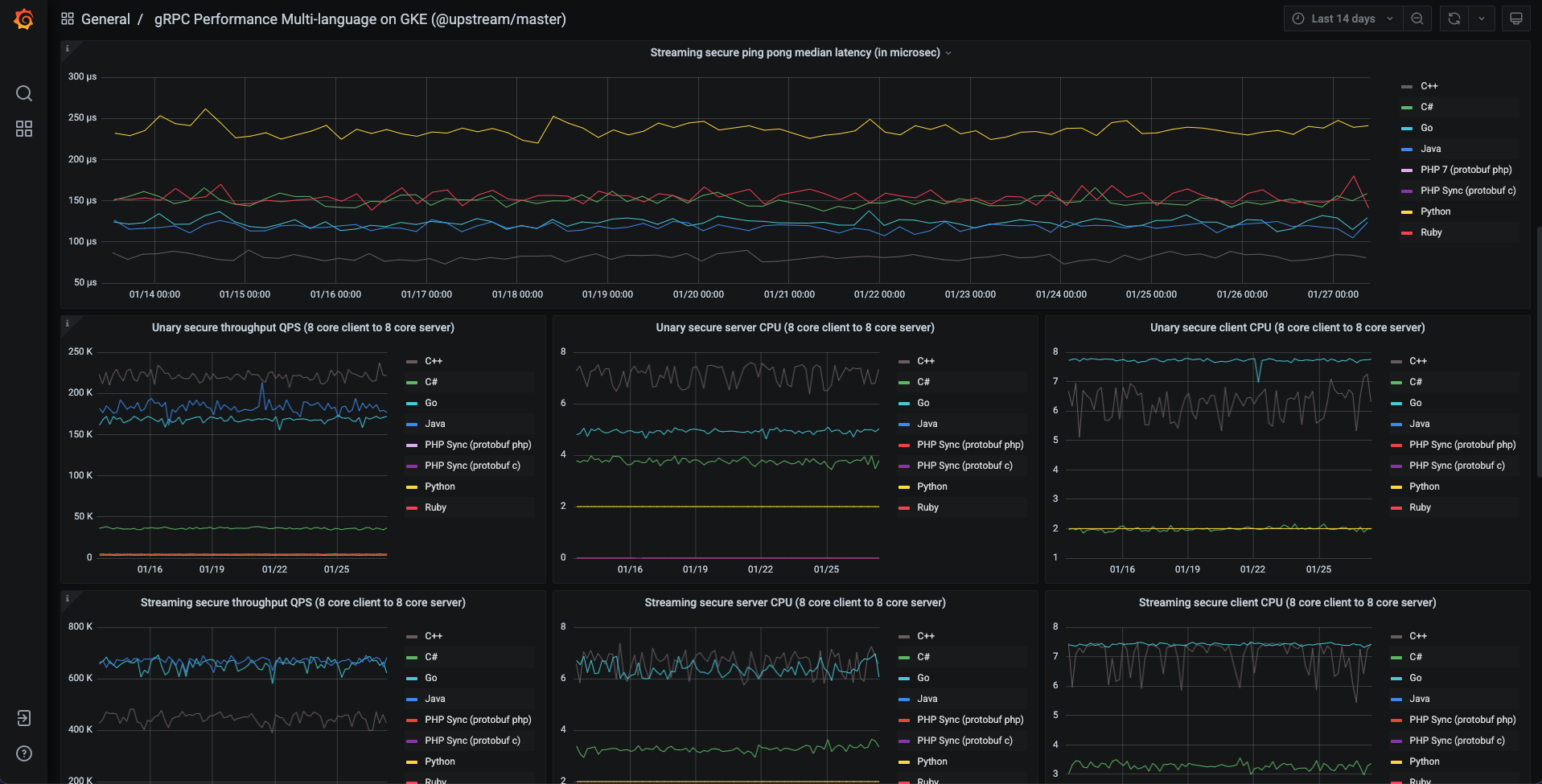
结果
对 GKE 上 gRPC 基准测试的结果和用户体验可以得出以下观察:
性能指标(延迟、QPS 等)产生的结果与 GCE 上的旧基准测试结果相同或更好。
在我们的基准测试集群中,GKE 中每个测试的 Pod 创建和删除开销很小(小于 15 秒)。
测试镜像已 Docker 化,并在每次测试时重新启动,从而带来多项好处:
结果更一致。
运行时错误很少发生。
系统分为定义明确的组件,从而简化了升级。
测试可以轻松并行化,从而加快执行时间。
实验更容易执行。
通过实验得出的最佳实践和见解示例:
为客户端和服务器使用
c2实例(实例类型对观察到的延迟及其方差以及测量的吞吐量影响很大)。GKE Pod 到 Pod 网络仅比原始 GCE 网络有很小的开销。您可以通过为基准测试 Pod 设置
hostnetworking:true来获得原始 GCE 网络性能。对于 Docker 环境下的 Java,JVM 可能无法自动检测可用的处理器数量。这可能导致非常悲观的结果,因为 gRPC 使用检测到的处理器数量来确定处理事件的线程池大小。一种解决方法是显式设置处理器数量。此解决方法已在此处实现。
自行运行
Test Infra 仓库中的代码允许任何用户创建集群、部署控制器、运行 gRPC 基准测试,并在自己的仪表盘上显示结果。如果您对性能感兴趣,并运行自己的基准测试,请告诉我们!